
Published Sep 11, 2024 • 3 min read

Our solution harnesses the power of AWS to deliver an effective and scalable text extraction process:
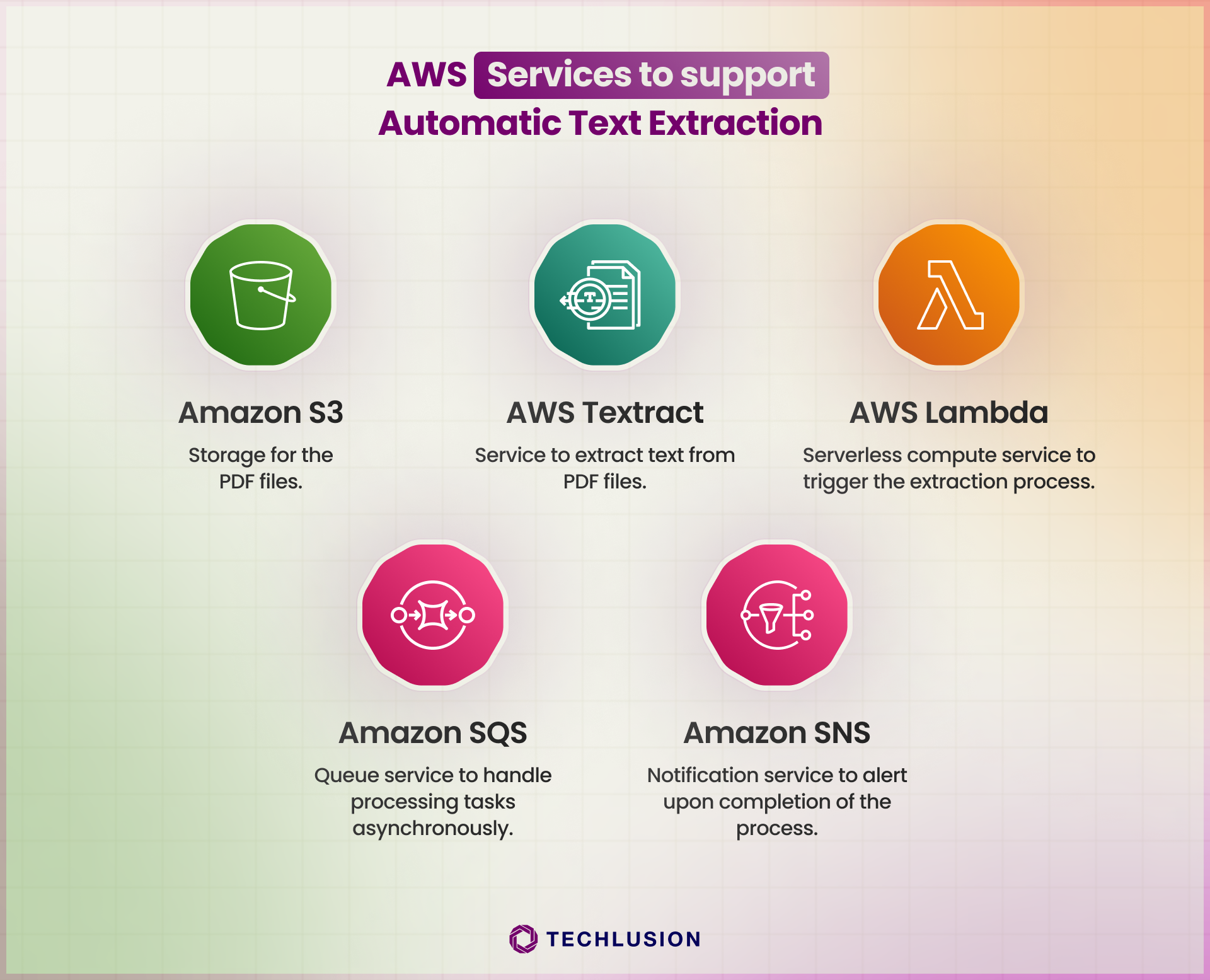
The architecture for our automated text extraction solution is designed to be both efficient and reliable:
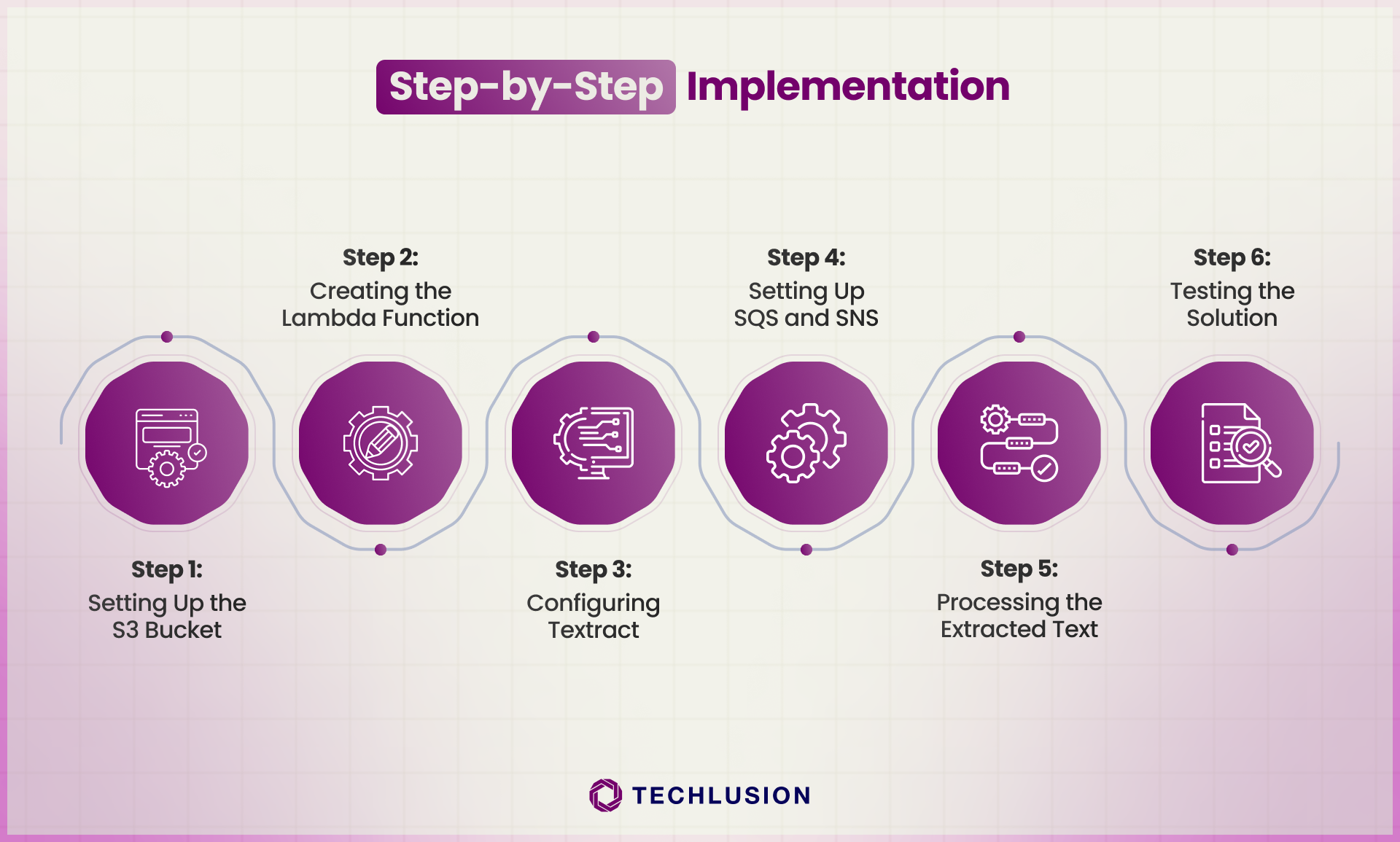
Step 1: Setting Up the S3 Bucket
Create an S3 bucket where users will upload their PDF files. Enable event notifications to trigger a Lambda function upon file upload.
aws s3api create-bucket --bucket pdf-extraction-bucket --region us-east-1
Configure the bucket to trigger a Lambda function when a new file is uploaded.
Step 2: Creating the Lambda Function
Create a Lambda function to handle the file upload event and invoke Textract.
import json
import boto3
def lambda_handler(event, context):
textract = boto3.client('textract')
s3_bucket = event['Records'][0]['s3']['bucket']['name']
document = event['Records'][0]['s3']['object']['key']
response = textract.start_document_text_detection(
DocumentLocation={
'S3Object': {
'Bucket': s3_bucket,
'Name': document
}
},
NotificationChannel={
'RoleArn': 'arn:aws:iam::account-id:role/TextractRole',
'SNSTopicArn': 'arn:aws:sns:region:account-id:TextractTopic'
}
)
return {
'statusCode': 200,
'body': json.dumps('Textract job started')
}
Step 3: Configuring Textract
Create an IAM role for Textract with the necessary permissions to read from S3 and write to SNS.
Step 4: Setting Up SQS and SNS
Create an SQS queue and SNS topic. Configure Textract to send job completion notifications to the SNS topic, which will then send messages to the SQS queue.
aws sns create-topic --name TextractTopic aws sqs create-queue --queue-name TextractQueue
Subscribe the SQS queue to the SNS topic.
Step 5: Processing the Extracted Text
Create another Lambda function to process the messages in the SQS queue, retrieve the extracted text from Textract, and send a notification via SNS.
import json
import boto3
def lambda_handler(event, context):
sqs = boto3.client('sqs')
textract = boto3.client('textract')
sns = boto3.client('sns')
for record in event['Records']:
message = json.loads(record['body'])
job_id = message['JobId']
response = textract.get_document_text_detection(JobId=job_id)
extracted_text = ''
for block in response['Blocks']:
if block['BlockType'] == 'LINE':
extracted_text += block['Text'] + '\n'
sns.publish(
TopicArn='arn:aws:sns:region:account-id:CompletionTopic',
Message=f'Text extraction completed: {extracted_text}'
)
return {
'statusCode': 200,
'body': json.dumps('Text processing completed')
}
Step 6: Testing the Solution
Upload a PDF file to the S3 bucket and verify that the text extraction process completes successfully. You should receive a notification with the extracted text.
By automating the text extraction process using AWS services, you can save time and reduce errors associated with manual extraction. This solution is scalable, cost-effective, and easy to implement, making it ideal for businesses of all sizes.
For more information about our services and how Techlusion can help you automate your business processes, visit our website techlusion.io or contact us at info@techlusion.io.
 Other interesting read : Choosing Between 💻Cross Platform vs. 📱Native Mobile App Development: What You Need to Know
Other interesting read : Choosing Between 💻Cross Platform vs. 📱Native Mobile App Development: What You Need to Know